
This was my first trip through ActionCable since sitting through DHHs keynote announcing it. At the time I was learning Phoenix and so I was less than blown away by this announcement of something that Phoenix had out of the box since day one.
Getting started proved to be the trickiest part. The documentation is good in spots however there are several places that left me guessing as to how to apply ActionCable to something that was not a chat application.
Luckily for me, for most of this I was pairing with my friend Stephanie who helped me get my head wrapped around this in the beginning and handled most of the initial setup as well as getting got all of this deployed.
To get started Stephanie found Michael Hartls’ Learn Enough Action Cable to Be Dangerous and it was by far the most helpful resource for us. One thing I struggled getting straight was an overview of the all the pieces involved and how they plugged together, so I’ll attempt to provide that later on.
My basic task was to allow a user to request a PDF which would be generated asynchronously and notify them when it was ready.
Starting with the outer layer first. My Connection code sets up the `current_user` pretty much exactly how the docs and blog posts I could find said to do:
# I wasn't entirely sure where to shove this, so it got stuffed in
# app/channels/application_cable/connection.rb
module ApplicationCable
class Connection < ActionCable::Connection::Base
identified_by :current_user
def connect
self.current_user = find_verified_user
end
private
def find_verified_user
if verified_user = env['warden'].user
verified_user
else
reject_unauthorized_connection
end
end
end
end
My understanding is that since the WebSocket’s share cookies with HTTP traffic the authentication is handled by the users normal login flow. As long as you are using a wss:// (the extra “s” standing for “secure” or something), you can trust generally that your user is logged in and use the session. So in my Connection I am simply using Devise’s Warden setup to load the User from the session.
And the JS to get your app to start making that connection, again straight from Hartl’s excellent examples and the docs:
// app/assets/javascripts/cable.js
//= require action_cable
//= require_self
//= require_tree ./cable
(function() {
this.App || (this.App = {});
App.cable = ActionCable.createConsumer();
}).call(this);
Since I had WebSockets available, I decided to use ActionCable’s @perform function to call a method on my channel to enqueue an ActiveJob rather than submitting an HTTP request. Inside the job, when the PDF was ready and uploaded to S3, we would broadcast on my channel a signed URL to download it from. Here’s my Channel code:
# app/channels/pdf_channel.rb
class PdfChannel < ApplicationCable::Channel
def subscribed
stream_from "pdf_#{params[:report]}_for_#{current_user.id}"
end
def enqueue_report_job(data)
report = Report.find(data['report'])
RenderReportToPdfJob.perform_later(current_user, report)
end
end
The subscribe method tells ActionCable which keys this channel is interested in. More on that later. The enqueue_report_job is what our JavaScript will trigger to start the process moving.
Here is my CoffeeScript to connect to it:
App.reportChannel = App.cable.subscriptions.create {channel: "ReportChannel", report: $('a[data-report-id]').data('report-id') },
anchorSelector: "a[data-report-id]"
connected: ->
@install()
disconnected: ->
@uninstall()
# Called when the subscription is rejected by the server.
rejected: ->
@uninstall()
received: (data) ->
if data.error
return @showError(data)
@displayPdfLink(data)
install: ->
$(@anchorSelector).on("click", (e) =>
link = $("a[data-report-id]")
@perform("enqueue_report_job", "report": $(@anchorSelector).data("report-id"))
)
uninstall: ->
$(@anchorSelector).off("click")
That CoffeeScript right there is my least favorite part. I am positive I’m doing something silly, and my sincerest hope is that by being wrong on the internet some kind soul will tell me just how silly I am.
So to my understanding, this is the general layout of what we have just created:
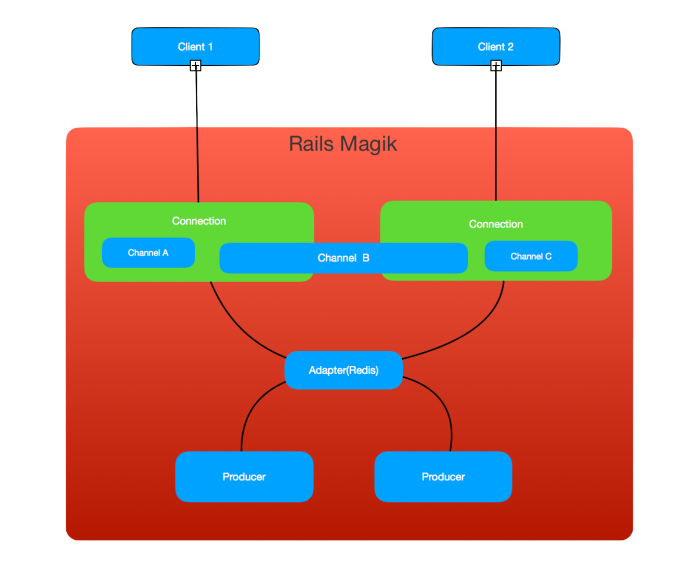
For now, ignore Client 2 and Channels B and C, they’re important later.
Client 1 has setup a connection, authenticated by her session, and subscribed to a channel for the specific report she is viewing. She has also registered a click handler for the “Generate PDF” button that will use ActionCable bi-directional trickery to call the enqueue_report_job method on the Channel object. At this point we have all the moving parts linked together.
The trickiest part of the whole process was figuring out the stream_from line. In many of the examples online, you see that line used to setup a stream for a chat room. In Hartl’s example he extends it one step further, showcasing the fact that you can call stream_from multiple times within a Channel.
This in the end was helpful but as multiple calls is not mentioned in the docs it also added to my confusion. Reading the docs I was trying to suss out which pieces were responsible for what. I’m not unfamiliar with WebSocket’s in general and I was trying to map my understanding of them to how Rails is using them.
Mainly, I was trying to figure out why, in the JavaScript when I setup the subscription I only had to specify the Report ID for the Channel, but in the stream_from line I needed to specify the Report ID and the current User ID in order to scope it correctly.
If you’re familiar with Redis PUB/SUBthen it’s pretty simple. Whatever you pass in to stream_from is passed directly to a Redis SUBSCRIBE command, so anything that gets PUBLISHED to that key will be forwarded down that channel.
So stream_from is used solely by the backend to map different Publishers to the appropriate Channels, which are already user specific based on that Users connection.
In Michael Hartl’s examples, this was used to send messages to room specific channels by using stream_from("room_#{params[:room}"), as well as streaming alerts to individual users by using stream_from "room_channel_user_#{message_user.id}".
In our report generation code, we want to stream completion notices to specific users for specific reports. So in our channel code we stream_from a key that specifies both a Report ID and a User ID. In order to do that, our background job has to have access to the User record to so that it can generate the same key.
I’m not sure why I got so hung up on that, but it was the thing that felt the trickiest to me.
So our job issues:
ActionCable.server.broadcast("report_#{report.id}_#{user.id}", reportUrl: url)
Which our Javascript will receive in its received function. As far as I can see, everything that gets sent down the channel will get passed to the same received function, but from the docs:
A channel encapsulates a logical unit of work
So it would seem you’re encouraged to subscribe to multiple Channels if you end up feeling like you’re overloading the received function.
Anyway, in our specific Javascript received, we take the URL for the uploaded Report and replace the “Generate PDF” link with a simple “Download PDF” link, easy peasy.
That’s how you build something besides a Chat App with ActionCable. The most challenging aspect was divining the responsibilities of all the moving parts. The Connections, Channels, Subscriptions, and stream_from all sort of fuzzed together. Once those become obvious ActionCable becomes a nicely organized and very functional solution to sending page updates to clients.
💝😽🎉